おべんきょうwiki
平均値シフト法
最終更新:
yahirohumpty
-
view
平均値シフト法
平均シフト,平均値シフト,ミーンシフト.法がついたりつかなかったり.
Mean shiftをどう訳すかでこうなったと思われる.
Mean shiftをどう訳すかでこうなったと思われる.
何をするもの?
何らかの分布が得られた時にそのピークを求める.
クラスタリングにも用いられる.
クラスタリングにも用いられる.
アルゴリズム
データがn個あったとして,
まず確率密度分布をカーネル密度推定で近似.
まず確率密度分布をカーネル密度推定で近似.
カーネルはガウス関数なら
これをなんやかんやして更新式は次のようになる.
注意点
更新式の については,別に元のデータセットを使う必要はない.
については,別に元のデータセットを使う必要はない.
適当に撒いたサンプル点から始まってもちゃんと収束してくれる.
という観点ではパーティクルフィルタに近い.
適当に撒いたサンプル点から始まってもちゃんと収束してくれる.
という観点ではパーティクルフィルタに近い.
K-meansのようにクラスタ数を決める必要はないが,
ラベリングか何かは収束後に必要になる.
ラベリングか何かは収束後に必要になる.
変な値を取ればうまくいかない.
pythonサンプルコード
#!/usr/bin/env python
import matplotlib.pyplot as plt
import math
import random
def create_dataset():
dat=[]
params=[(5.0,1.0),(10.0,1.5),(15.0,1.0)]
for p in params:
for i in range(100):
dat.append(random.gauss(p[0],p[1]));
return dat
def proc_meanshift(dat,sigma=1.0):
sqsigma=sigma*sigma
sdat=range(20)
for j in range(10):
for i in range(len(sdat)):
sdat[i]=update_sample(sdat[i],dat,sqsigma)
return sdat
def update_sample(sample,dat,sqsigma):
kj=0.0
kjd=0.0
for d in dat:
dif=sample-d
k=math.exp(-0.5*(dif*dif/sqsigma))
kj=kj+(k*d)
kjd=kjd+k
return kj/kjd
def plot_dataset(dat):
daty=[-0.5]*len(dat)
plt.scatter(dat,daty)
plt.hist(dat)
plt.show()
# usage:
# dat=create_dataset()
# plot_dataset(dat)
## 元の分布データを正規乱数から生成して表示して確認
# sdat=proc_meanshift(dat)
# plot_dataset(sdat)
## 1.0おきに配置したサンプルを平均シフトを使って移動
## 同様に表示して結果を確認
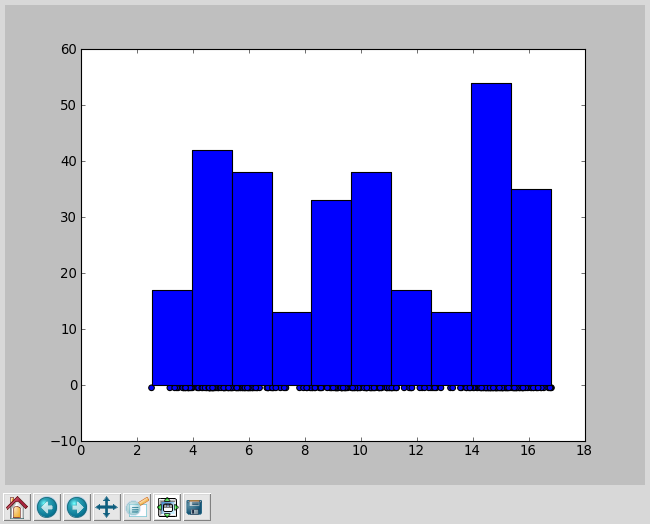
実行例・入力データセットとヒストグラム

計算結果
参考文献
http://sugiyama-www.cs.titech.ac.jp/~sugi/2007/Canon-MachineLearning22-jp.pdf
「平均シフト」と記述.その他のクラスタリング手法についても.
「平均シフト」と記述.その他のクラスタリング手法についても.
